Analyse von Umfragedaten mit künstlicher Intelligenz - Anwendungsbeispiele und Ablauf


Immer wieder sind Kunden auf uns zugekommen, die Umfragen mit Couchsurvey, oder einer anderen Umfrageplattform, durchgeführt haben, in denen es eine enorm hohe Anzahl an Freitext-Antworten gab - häufig viele tausend. Versucht man diese Textdaten manuell durchzulesen und zu klassifizieren, kann dieses Vorhaben mehrere Wochen dauern.
Um unseren Kunden diese Arbeit stark zu erleichtern, haben wir eine künstliche Intelligenz entwickelt, die in der Lage ist, Textdaten automatisiert zu analysieren und zu klassifizieren. Besonders ist, dass die Textdaten ein beliebiges Thema haben können und der Algorithmus stets in der Lage ist, die Daten zu klassifizieren. Sie erhalten als erstes Ergebnis einen Überblick über die Themen, die im Datensatz erwähnt wurden, relative und absolute Häufigkeiten dieser Themen sowie andere statistische Kennzahlen.
Ebenfalls bietet die von uns entwickelte künstliche Intelligenz eine Sentiment-Analyse. Das bedeutet, dass der Algorithmus auch in der Lage ist die Stimmung zu erkennen, in der die Personen beim Schreiben der jeweiligen Texte mit hoher Wahrscheinlichkeit gewesen sind.
Wie arbeitet die künstliche Intelligenz und wonach sucht sie?
Jeder Textbeitrag, der von einer Person erzeugt wurde, wird einzeln an die KI übergeben und kann eine beliebige Anzahl an Sätzen aufweisen. In der Praxis bestehen die einzelnen Beiträge meist aus einem oder zwei kurzen Sätzen. Sollte ein Textbeitrag aus mehr als einem Satz bestehen, werden die Sätze einzeln von der KI verarbeitet.
Vorbereiten der Daten für die Analyse
Bevor der Satz analysiert wird, muss der Satz um alle Dinge, die für die KI nicht notwendig sind, bereinigt werden. Dafür wird im ersten Schritt jedes Wort vom Algorithmus klein geschrieben, danach werden jegliche Satzzeichen entfernt.
Ich bin wirklich sehr zufrieden mit der Veranstaltung, weil mir die Vorträge gut gefallen haben.
Ein solcher Satz würde nach den ersten Schritten so aussehen:
ich bin wirklich sehr zufrieden mit der veranstaltung weil mir die vorträge gut gefallen haben
Nun wird der Satz "tokenisiert" (d.h. in einzelne, für Maschinen verarbeitbare Elemente zerlegt)- dieser Schritt ist wichtig, damit der Satz von der KI überhaupt verarbeitet werden kann.
['ich', 'bin', 'wirklich', 'sehr', 'zufrieden', 'mit', 'der', 'veranstaltung', 'weil', 'mir', 'die', 'vorträge', 'gut', 'gefallen', 'haben']
Als nächstes werden die Stoppwörter aus dem Satz entfernt. Diese Wörter können problemlos entfernt werden, da sie sehr häufig auftreten und in der Regel keine Relevanz für den Textinhalt besitzen. Beispiele für Stoppwörter sind unter anderem "ich, "bin", "wirklich", "mit", "ist", "an", "ab", "bei", "der","weil", "mir", "die", "haben" - für verschiedene Sprachen existieren öffentlich einsehbare Listen mit Stoppwörtern.
Je nach Art der Analyse kann das Entfernen von Stoppwörtern auch kontraproduktiv sein und hängt häufig vom Einzelfall bzw. der Art der Daten und der gewünschten Analyse ab. Unser Erfahrungswissen ermöglicht es uns zu entscheiden wann die Stoppwörter entfernt werden sollten und wann nicht.
['zufrieden', 'veranstaltung', 'vorträge', 'gut', 'gefallen']
Nun kann "Lemmatization" durchgeführt werden, das bedeutet, dass die Worte auf ihr Lemma reduziert werden.
['zufrieden', 'veranstaltung', 'vortrag', 'gut', 'gefallen']
Als nächstes ist "Part of Speech Tagging (POS)" an der Reihe. Dabei werden die einzelnen Wörter einer Wortart zugeordnet.
['zufrieden' (adjektiv), 'veranstaltung' (nomen), 'vortrag'(nomen), 'gut'(adjektiv), 'gefallen' (verb)]
Nun haben wir die Daten so aufbereitet, dass das System diese verarbeiten kann.
Gruppieren nach Themen
Das System ist nun in der Lage alle Nomen, die in den einzelnen Texten vorkommen, zu speichern und zu zählen. Es werden darüber hinaus leicht verständliche Grafiken vom System erzeugt, die die Themen z.B. mit Hilfe von Säulendiagrammen darstellen.
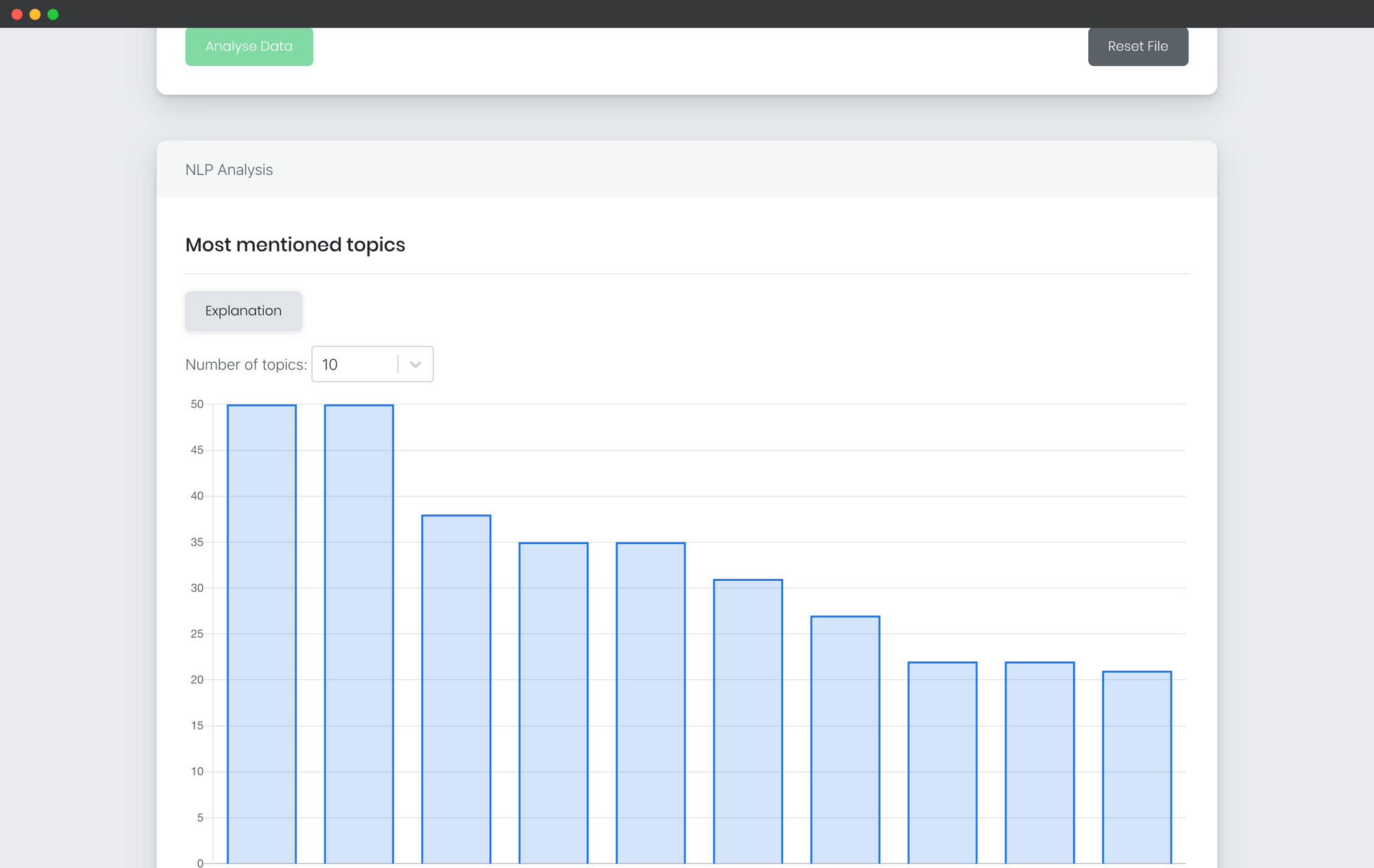
Die Y-Achse zeigt die absoluten Häufigkeiten. Auf der X-Achse sind die verschiedenen Themen dargestellt.
So erhält man eine klare und einfache Übersicht über die Themenschwerpunkte, die in den Freitext-Fragen erwähnt wurden. Man kann so auf einen Blick genau sehen, was den Teilnehmenden besonders wichtig war und zu welchen Themen sich geäußert wurde.
Sentiment Analyse
Für jeden Satz, den die KI analysiert, wird neben der Extraktion der Themen auch eine Sentiment Analyse durchgeführt. Dabei wird die Stimmung, die die Person beim Schreiben des Textes gehabt hat, bzw. die Stimmung, die der Text vermittelt, bestimmt. Die Stimmung wird mit Hilfe des Sentiment-Scores, einer Zahl zwischen -1 und 1, angegeben. Je dichter das Sentiment eines Satzes an der oberen Grenze 1 liegt, desto positiver ist das Sentiment - je dichter das Sentiment an der untere Grenze -1 liegt, desto negativer.
Das durchschnittliche Sentiment (Average Sentiment) gibt die Grundstimmung aller Textbeiträge, die von der KI analysiert wurden, wieder - ein positiver Wert spricht für eine positive Grundstimmung, ein negativer für eine negative Grundstimmung. Mit dem Wert "Best Sentiment" wird beschrieben, welchen Sentiment-Score der positivste Textbeitrag hat, mit dem "Worst Sentiment" wird der Sentiment-Score des negativsten Beitrages angegeben.
Schließlich werden die einzelnen Beiträge einer von 4 Gruppen von "Very positive" bis "very negative" zugeordnet. Die Werte, um einen Beitrag in eine der Gruppen "Very positive", "Positive", "Negative" und "Very negative" einzuteilen, sind von der stackOcean GmbH festgelegt worden und basieren auf Erfahrungswerten. Sentiment-Scores mit einem Wert unter null werden allerdings immer negativ klassifiziert sein - Sentiment-Scores mit einem Wert oberhalb von null immer positiv. Die absoluten Häufigkeiten der Textbeiträge in den einzelnen Gruppen sind unter den Gruppen dargestellt.
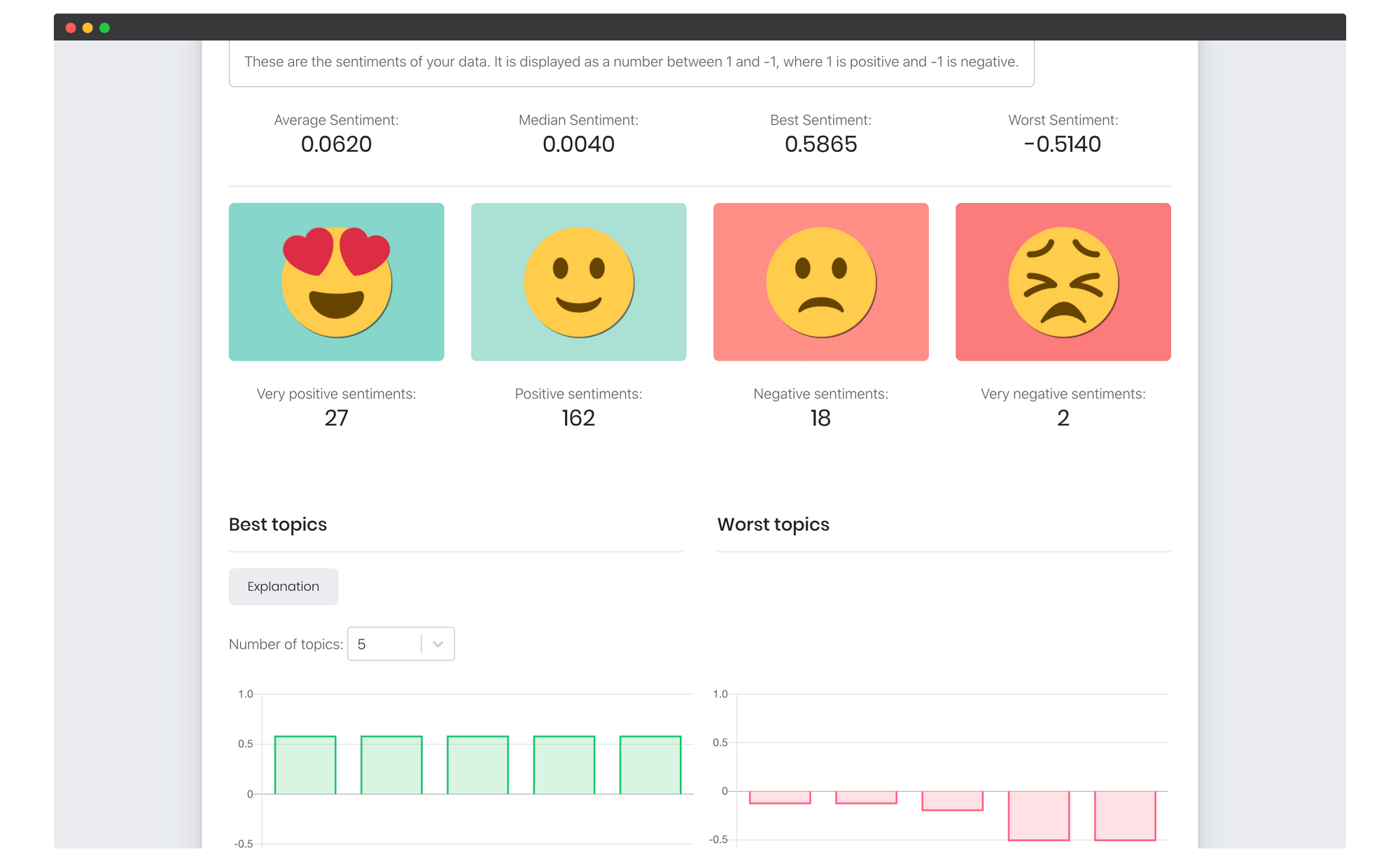
Das Beispiel "Ich bin wirklich sehr zufrieden mit der Veranstaltung, weil mir die Vorträge gut gefallen haben." würde ein Sentiment von ~0.5 haben und in die Gruppe "Very positive" eingeteilt werden.
Durch die Sentiment Analyse können wir zusätzlich zu den Themengebieten auch die Stimmung erfassen, die in den Textbeiträgen vermittelt wurde. Durch die Kombination dieser beiden Kennzahlen erhält man einen aussagekräftigen ersten Eindruck der erhobenen Daten.
Export der Daten
Der ursprüngliche Datensatz wird mit den gewonnenen Erkenntnissen der Analyse angereichert und kann unseren Kunden auf Wunsch zur Verfügung gestellt werden. So besteht die Möglichkeit mit den erkannten Themen und Sentiments weiter zu arbeiten. Der zur Verfügung gestellte Datensatz sieht so aus, dass im Tabellen-Dokument (.csv) eine weitere Spalte für das Sentiment und eine weitere Spalte für die erkannten Themen erzeugt wird.